一次漫长的customer case问题定位 - OOM
在去年九月份,我接到了入职以来第一个PR (Problem Report?),来自🇦🇺的一个cloud service provider。当时没什么经验的我看着这个customer case手足无措,毫无头绪,最终在团队的帮助下给了客户一个凑合的解决方案。如今过去了一年,没想到自己还在和这个客户打交道,依旧是和去年差不多的问题。一年的磨练多少有点进步,写下来记录一下。
Round 1
去年九月,客户向我们报了一个看似影响不大却很诡异的问题——每运行一段时间,UI上的一个计数就不再更新,重启之后大概率可以恢复正常。除此之外系统似乎还在正常运行,基本功能也不受影响。这个计数由系统中每分钟执行一次的Quartz job刷新,经过排查发现,不止这个job,客户环境里其他所有的定时任务都处于停滞状态,日志里相关的报错是
Caused by: java.lang.NoClassDefFoundError: Could not initialize class org.postgresql.util.GT
还有一些OutOfMemory。
参考stackoverflow/questions/53637617等,我们很快把这两者联系起来。基本可以判定是系统某时刻内存溢出,导致Quartz job崩溃。为了验证这个观点,我们做了两件事:
-
找客户要了Quartz相关的table dump——然而并没有什么发现,qrtz_triggers等几个表里的数据看起来没什么异样,没有积攒的misfired job。但事实就是所有的定时任务都不再被触发。
-
在我们本地的环境进行了验证: 写一个专门用来触发内存溢出的定时任务,例如
import org.quartz.*; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.stereotype.Component; import java.util.ArrayList; import java.util.List; @PersistJobDataAfterExecution @Component public class TestJob implements Job { private static final Logger logger = LoggerFactory.getLogger(BucketMetricsJob.class); public void subscribe() { if (logger.isDebugEnabled()) { logger.debug("Starting create OutOfMemoryError."); } } @Override public void execute(JobExecutionContext context) throws JobExecutionException { List<byte[]> list = new ArrayList<>(); for (int i = 0; i < 1000; i++) { list.add(new byte[1024 * 1024]); // add a 1M object each time in the loop } } }然后把java vm的内存设小一些:
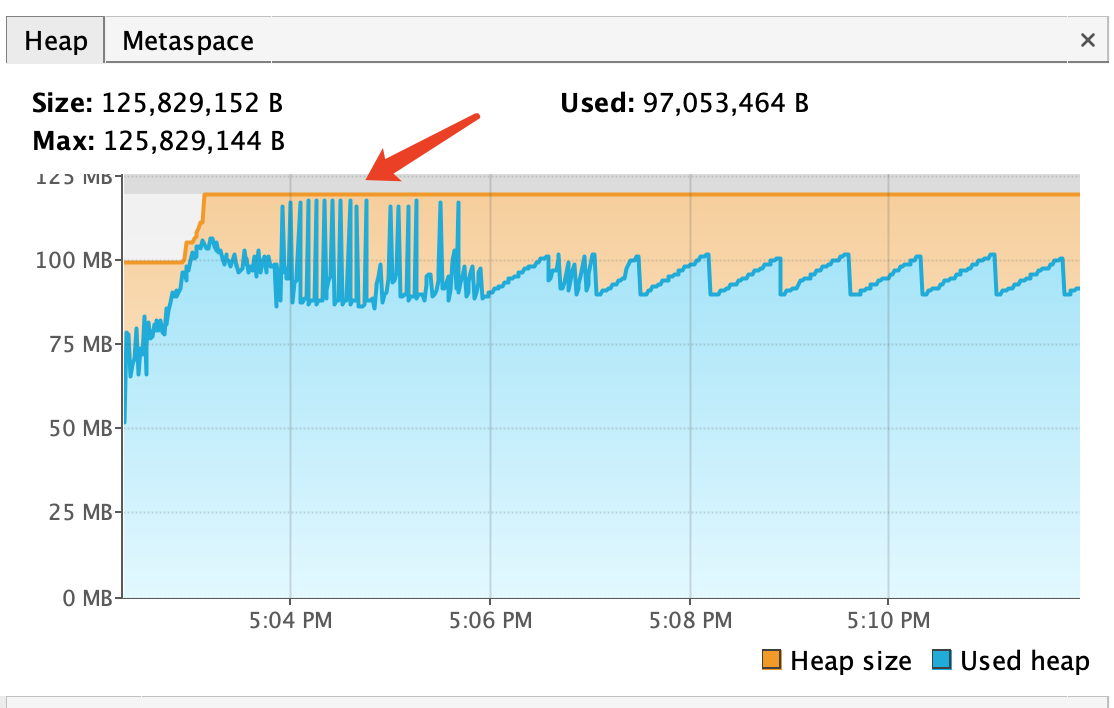
-Xms100m -Xmx120m运行之后在VisualVM(或者其他java内存工具)中可以看到类似这样的java heap:
测试下来在内存溢出后,Quartz确实全线崩溃,但其他线程并没有受到影响,而Quartz并没有记录misfired job,在一段时间后也没有自动恢复,和客户报的现象基本一致。
大概找到问题之后,就开始想解决方案。讨论了很多,试了很多,也排除了很多:
方案1 (未采用): 给每个定时任务设置超时时间,一旦超过某个时间还没完成,就停止该任务。 事实是受系统环境影响,不同客户环境、不同任务的执行时间可能会非常不同。也许一个任务会执行很久,无法根据经验判断“超时”的阈值。
方案2 (未采用): 在每个任务里启用heart beat,一旦发现某个定时任务线程被block住,就结束该线程。
这是组里几个大佬都提议的做法,听起来合情合理,但我试下来也存在一些困难(也可能是因为我菜)。首先我很难在一个定时任务线程里启用heart beat,是任务执行过程中需要经常中断以发送heart beat信号?或许是再启用一个子线程?更大的困难在于,java中对于线程的stop()方法已弃用(弃用的理由十分合理,参考《Why are Thread.stop, Thread.suspend and Thread.resume Deprecated?》),如果想停止线程只能用interrupt()标记中断。但如果这个线程已经被block了,它又怎么去监控这个interrupt标志位呢?
方案3 (最终): 在2的基础上,最终采用的方案依旧是增强Quartz的监控功能,大致来说分为两方面。第一是增加JobListener,在我们的日志里将记录每次job开始、结束、下一次触发的时间,同时在job结束时,会记录这个job处理的总时长和当前的java heap大小。这个改动本质上对解决问题没有任何帮助,只是帮助我们更好地分析问题。第二个改动是在job中catch异常(NoClassDefFoundError和OutOfMemoryError),一旦发现内存溢出,就触发异常处理程序:
private void scheduleExceptionHandler(JobExecutionContext context, Error e) {
try {
logger.error("Job execution failed. ", e);
Scheduler scheduler = context.getScheduler();
scheduler.standby();
logger.debug("Call for garbage collection.");
System.gc();
scheduler.start();
} catch (SchedulerException schedulerException) {
throw new ForbiddenException("RELOAD_SCHEDULER_FAILED", schedulerException.getMessage());
}
}
也就是说先让这个线程standby,然后让系统做gc,然后再恢复。
这是方案甚至不能让我自己满意,也为后续埋了雷。具体来讲:1. 我们没有找到导致OOM的原因,也许是定时任务里的OOM,也或许是其他线程里的,单纯catch定时任务里的OOM异常并不能从根本上解决问题。 2. System.gc()的行为是否有效十分存疑,我对java垃圾回收了解不多,但隐约觉得单纯调这个命令不能解决问题,按理说一旦出现内存溢出,java应该自己就会进行垃圾回收,但很显然在我们的case里垃圾回收并没有使系统恢复正常。
但这个方案最终还是被当作解决方案给了客户,客户在安装这个hot fix之后在一段时间内也确实没有再来给我们报bug。虽然我认为没有找到根本原因,但也实在不想再处理这个PR了。
Round 2
客户再次找到我们是在今年二月,这次的PR并不是我处理的,因此简单记录一下我了解的情况。
这次客户报的问题是某些时刻CPU使用率意外地高,导致服务无法处理其他请求,同样地,重启可以解决这一问题。从他们的日志里可以看到吞吐量并不高,有Quartz job偶尔的OOM报错,但CPU利用率高得不正常。最终,我们组的资深后端将问题定位到某段逻辑的递归调用上,客户操作导致的递归调用层数比我们预想的多很多,因此导致CPU高使用率。
按这个优化思路,我们再次给客户提供了hot fix,客户使用后也没再找我们。日志里的OOM问题被认为是和CPU使用率高相关的,因此没再受关注。
Round 3
七月中旬,这个倒霉的客户又来了。带来的是同样的问题:UI上的计数不更新。但很遗憾,这次他们在重启时也偶尔失败,java在打印出SPRING这个标之后就卡住了,日志里对于启动失败没有任何报错。老问题没解决,而且有越来越影响使用的趋势,我开始感到惭愧并同情这个客户了🫠。
有了之前的经验,这次我直奔Quartz相关的日志,果然又是内存溢出导致任务不执行。此外,在成功的重启后,可以看到系统触发了一些一个月前的misfired job——也就是说在内存溢出后系统根本没有靠垃圾回收恢复正常。这次我参考stackoverflow/questions/618265尝试找客户要thread dump、heap dump和postgres dump:
Please execute the following commands to generate a thread dump and heap dump for application:
a) Run jps and find the PID of Application:
jps
b) Thread dump:
jstack -l {PID} > {file_path_in_txt}
For example: jstack -l 21715 > thread-dump.txt // It will generate a txt file in home path.
c) Heap dump:
jmap -dump:live,file={file_path_in_hprof} {PID}
For example: jmap -dump:live,file=heap-dump.hprof 21715
If possible, please also provide dumps of the following tables: qrtz_simple_triggers and qrtz_triggers. The commands are:
pg_dump -U {username} {DBname} -t qrtz_simple_triggers > qrtz_simple_triggers-dump.sql
pg_dump -U {username} {DBname} -t qrtz_triggers > qrtz_triggers-dump.sql
我想这是个很好的思路,能知道是否产生了线程拥堵,以及一段时间内heap的使用情况。然而客户随后反馈说,jps这个命令没有。。看来是只装了jre没有jdk。于是只要到了Quartz相关的两个表的dump,在其中发现了一些一个月前的misfired job,没什么帮助。
但这次的情况稍有不同,客户为了增加稳定性设置了四个服务节点,通过负载均衡器访问。四个节点在一段时间内都出现了内存溢出,也就是说我有四个样本可以参考。在翻日志的时候,我发现四个服务节点关于OOM的报错都指向了同一个定时任务(暂称为JOB1)。而在进一步追要的日志中,有三个misfired job被触发后没有结束(在日志的时间范围内没有结束),其中就包括了JOB1。继续追查发现JOB1似乎会卡在一个及其平常的地方(四个节点中有两个的报错也指向了这一操作):
repository.deleteByAAA(aaa)
再往里找一层:
@Transactional(isolation = Isolation.READ_COMMITTED)
void deleteByAAA(String aaa);
这里JOB1用来定时清空一些数据库中无用的数据,数据库靠Hibernate JPA连接。和客户求证后发现,他们在进行这个操作时需要删除某张表中的上千万行记录,直接使用Hibernate方法会使得这些记录先load到内存中,导致OOM。
这个发现看起来十分符合逻辑,于是参考Deleting 1 millions rows in SQL Server以及Deleting Objects with Hibernate提出了几种优化方案:
方案1: 先select count(*)计算要被删除的数据数量,一旦超过某个量级就分批删除
方案2: 使用Native Query删除
方案3: 设置一个delete标志位,暂时不会真正将数据删除,只是查询的时候忽略,等系统空闲时再逐步删除
因为方案2的改动最小,所以从方案2开始验证。于是我将原来的方法改为了Native Query:
@Transactional(isolation = Isolation.READ_COMMITTED)
@Modifying(flushAutomatically = true, clearAutomatically = true)
@Query(value = "DELETE FROM table_name WHERE AAA = :aaa", nativeQuery = true)
void deleteByAAA(@Param("aaa") String aaa);
为了验证这个更改是否有效,我向数据库对应的table里插入了10,000,000条记录,触发JOB1,利用VisualVM实时查看heap使用情况。下图分别是原来的实现与改动后在删除一千万条数据时的情况:
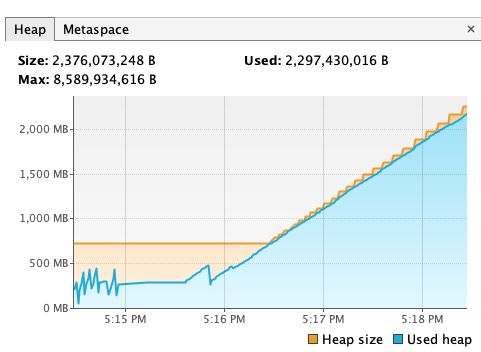
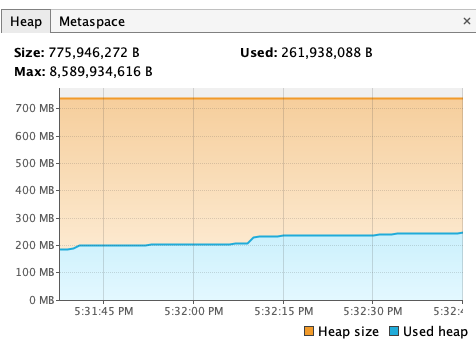
对于第一张图,在我手动结束应用进程前,heap占用不断增大的状况并没有停止。而Native Query的delete操作并没有带来明显的内存消耗,在等待了两分钟左右后我进行数据库查询,发现这一千万条数据已经被删掉了。这说明大规模的delete操作确实很可能是造成OOM、进而导致Quartz崩溃的根源,而Native Query可以改善这一问题。至于服务重启失败,我认为很有可能和数据库“失联”有关。
目前已经将hot fix提交给客户,希望这能帮他们从根本上解决问题。……please
(两周后续:客户应用了这一更改,目前没有问题反馈)