k8s学习笔记-黑马
为了准备CKA看了b站上黑马程序员的k8s课程,总体来说比较基础,也有一些过时的内容,但优点在于简单、全面、清晰。参考评论区的笔记记录一下。
1 k8s介绍
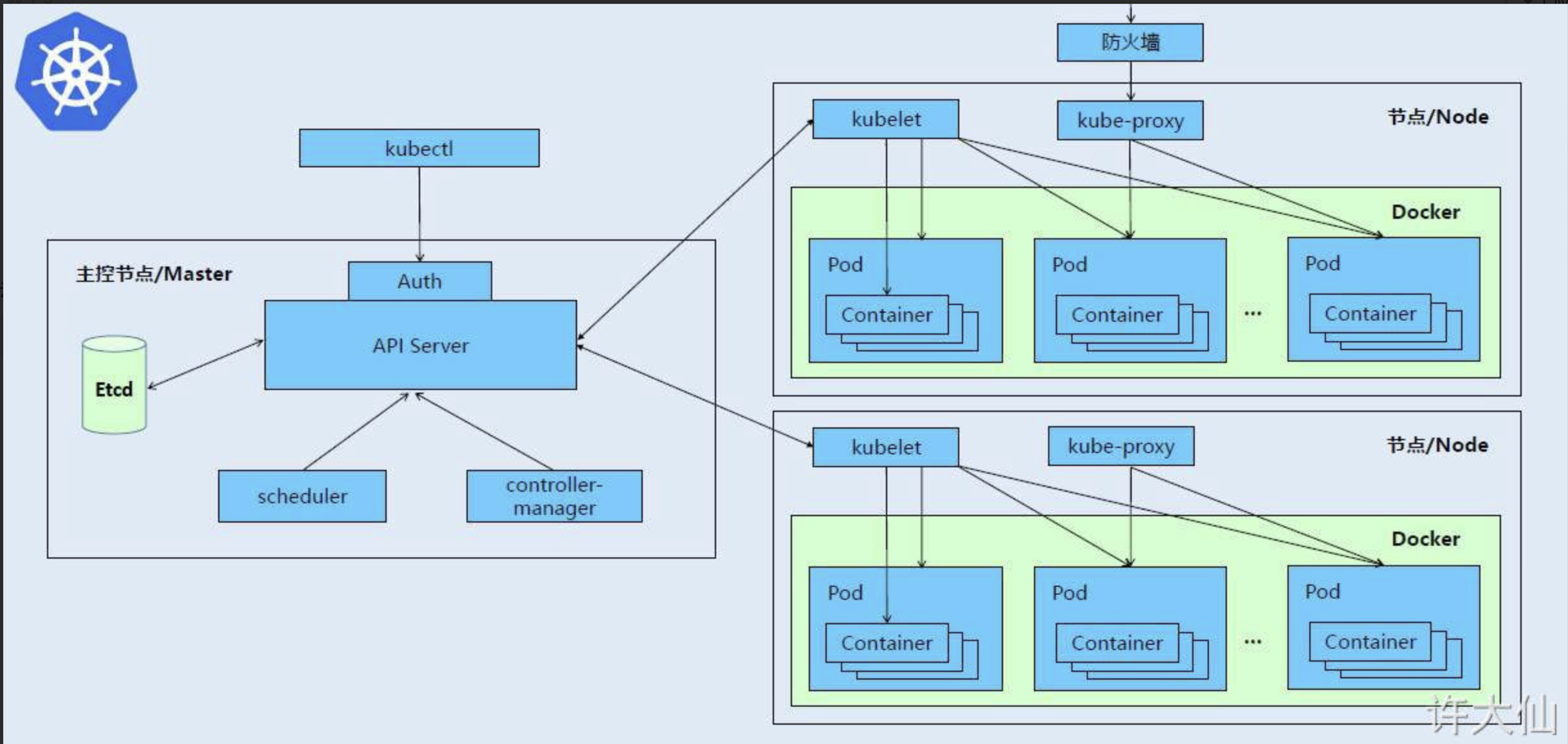
k8s组件
kubernetes 集群主要由控制节点(master) 和 工作节点(node)构成,每个节点上有不同的组件。
-
控制节点(master):集群的控制平面,负责集群的决策。
-
API Server:集群操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制。
-
Scheduler:负责集群资源调度,按照预定的调度策略将 Pod 调度到相应的 node 节点上。
-
ControllerManager:负责维护集群的状态,比如程序部署安排、故障检测、自动扩展和滚动更新等。
-
Etcd:负责存储集群中各种资源对象的信息。
-
-
工作节点(node):集群的数据平面,负责为容器提供运行环境。
-
Kubelet:负责维护容器的生命周期,即通过控制 Docker ,来创建、更新、销毁容器。
-
KubeProxy:负责提供集群内部的服务发现和负载均衡。
-
Docker:负责节点上容器的各种操作。
-
相关概念
-
Master:集群控制节点,每个集群至少有一个 Master 节点。
-
Node:工作负载节点,Master 分配容器到 Node上,Node 上的 Docker 负责容器的运行。
-
Pod:Kubernetes 的最小控制单元,容器运行在 Pod 中,一个 Pod 中可以有一个或多个容器。
-
Controller:控制器,通过它来实现对 Pod 的管理,比如启动 Pod 、停止 Pod 、伸缩 Pod 的数量等。
-
Service:Pod 对外服务的统一入口,可以维护同一类的多个 Pod 。
-
Label:标签,用于对 Pod 进行分类。
-
NameSpace:命名空间,用来隔离 Pod 的运行环境。
2 集群搭建
…
3 资源管理
资源管理介绍
yaml介绍
- 数组用
- - 多个yaml用
---分割
资源管理方式
-
命令式对象管理:直接使用命令去操作kubernetes的资源
kubectl [command] [type] [name] [flags]-
command:指定要对资源执行的操作,比如create、get、delete。
kubectl --help -
type:指定资源的类型,比如deployment、pod、service。
kubectl api-resources -
name:指定资源的名称,名称大小写敏感。
-
flags:指定额外的可选参数 (例如
-o wide,-o yaml)。
-
-
命令式对象配置:通过命令配置和配置文件去操作kubernetes的资源
kubectl create/patch/delete -f nginx-pod.yaml -
声明式对象配置:通过apply命令和配置文件去操作kubernetes的资源 (相当于create和patch)
kubectl apply -f nginx-pod.yaml
4 实战入门
namespace
Namespace的主要作用:实现多套系统的资源隔离或者多租户的资源隔离。
Kubernetes在集群启动之后,会默认创建几个namespace:
>> kc get ns
NAME STATUS AGE
default Active 19d # 未指定ns的对象会被分配在default命名空间
kube-node-lease Active 19d # 集群节点之间的心跳维护,v1.13开始引入
kube-public Active 19d # 此命名空间的资源可以被所有人访问(包括未认证用户)
kube-system Active 19d # 包含kubernetes系统创建的资源
pod
-
Pod是kubernetes集群管理的最小单元,程序要运行必须部署在容器中,而容器必须存在于Pod中。
-
Pod可以认为是容器的封装,一个Pod中可以存在一个或多个容器。
label
Label以key/value键值对的形式附加到各种对象上,如Node、Pod、Service等。可以通过Label实现资源的多维度分组,进行资源分配、调度、配置和部署等管理工作。
两种Label Selector:
(1) 基于等式的Label Selector:
- name=slave:选择所有包含Label中的key=“name”并且value=“slave”的对象。
- env!=production:选择所有包含Label中的key=“env”并且value!=“production”的对象。
(2) 基于集合的Label Selector。
- name in (master,slave):选择所有包含Label中的key=“name”并且value=“master”或value=“slave”的对象。
- name not in (master,slave):选择所有包含Label中的key=“name”并且value!=“master”和value!=“slave”的对象。
命令行:
-
添加label:
kubectl label pod xxx key=value [-n ns] -
查看label:
kubectl get pod xxx [-n ns] --show-labels -
筛选标签:
kubectl get pod -l key=value [-n ns] --show-labels -
删除标签:
kubectl label pod xxx key- [-n ns]
deployment
deployment是一种pod控制器
命令行:
-
创建deployment:
kubectl create deploy xxx [-n ns] -
指定replica:
kubectl scale deploy xxx [--replicas=3] [-n ns] -
删除:
kubectl delete deployment xxx [-n ns]
service
Service是一组同类的Pod对外的访问接口。借助Service,应用可以实现服务发现和负载均衡。
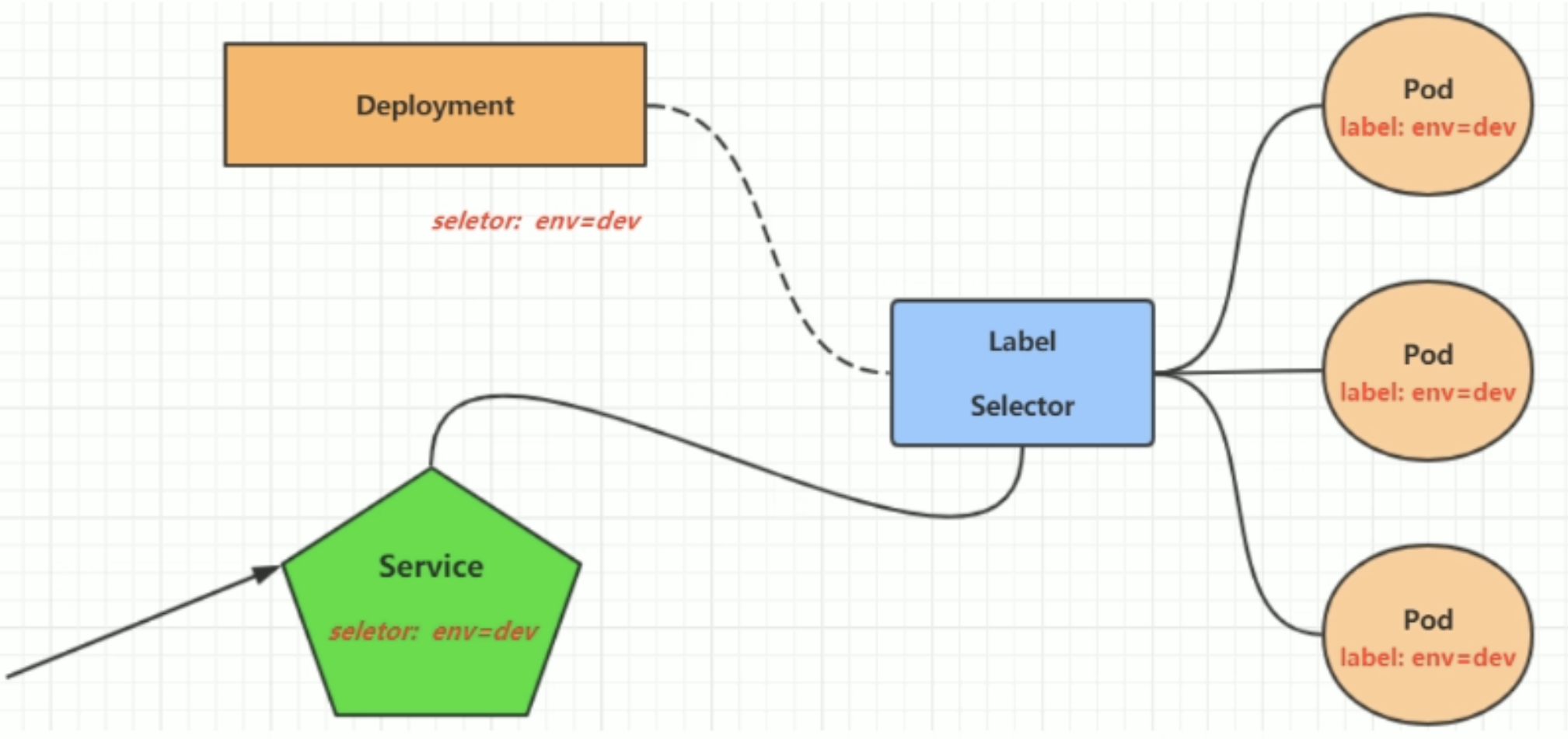
命令行:
-
创建cluster内部可访问的service:
# 暴露service kubectl expose deploy nginx --name=svc-nginx1 --type=ClusterIP --port=80 --target-port=80 -n ns -
创建cluster外部可访问的service:
# 暴露service kubectl expose deploy nginx --name=svc-nginx2 --type=NodePort --port=80 --target-port=80 -n ns -
对比这两者:
>> kc get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx NodePort 10.96.123.164 <none> 80:30884/TCP 7d svc-nginx ClusterIP 10.96.227.84 <none> 80/TCP 5s如果正常部署,NodePort类型的service可以通过
本机ip:30884访问,但我的cluster来自于kind,并不能这样访问。
5 Pod详解
pod结构
pod包含一个或多个容器:
- user container 用户容器
- pause container 根容器
查看pod的可配置项:
kubectl explain pod
kubectl explain pod.metadata # 用.查看子属性
一级属性:
-
apiVersion :版本,用
kubectl api-versions查询。 -
kind :类型,用
kubectl api-resources查询。 -
metadata :元数据,主要是资源标识和说明,常用的有name、namespace、labels等。
-
spec :描述,这是配置中最重要的一部分,里面是对各种资源配置的详细描述。
-
status :状态信息,里面的内容不需要定义,由kubernetes自动生成。
在上面的属性中,spec是接下来研究的重点,继续看下它的常见子属性:
-
containers <[]Object>:容器列表,用于定义容器的详细信息。
-
nodeName :根据nodeName的值将Pod调度到指定的Node节点上。
-
nodeSelector <[]map> :根据NodeSelector中定义的信息选择该Pod调度到包含这些Label的Node上。
-
hostNetwork :是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络。
-
volumes <[]Object> :存储卷,用于定义Pod上面挂载的存储信息。
-
restartPolicy :重启策略,表示Pod在遇到故障的时候的处理策略。
pod.spec.containers配置
kubectl explain pod.spec.containers
一些重要属性:
KIND: Pod
VERSION: v1
RESOURCE: containers <[]Object> # 数组,代表可以有多个容器FIELDS:
name <string> # 容器名称
image <string> # 容器需要的镜像地址
imagePullPolicy <string> # 镜像拉取策略
command <[]string> # 容器的启动命令列表,如不指定,使用打包时使用的启动命令
args <[]string> # 容器的启动命令需要的参数列表
env <[]Object> # 容器环境变量的配置
ports <[]Object> # 容器需要暴露的端口号列表
resources <Object> # 资源限制和资源请求的设置
镜像拉取策略 spec.containers.imagePullPolicy
三种镜像拉取策略:
- Always:总是从远程仓库拉取镜像
- IfNotPresent:本地有则使用本地镜像,本地没有则从远程仓库拉取镜像
- Never:只使用本地镜像,从不去远程仓库拉取,本地没有就报错
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-imagepullpolicy
namespace: dev
spec:
containers:
- name: nginx # 容器名称
image: nginx:1.17.1 # 容器需要的镜像地址
imagePullPolicy: Always # 用于设置镜像的拉取策略
- name: busybox # 容器名称
image: busybox:1.30 # 容器需要的镜像地址
默认值说明:
-
如果镜像tag为具体的版本号,默认策略是IfNotPresent
-
如果镜像tag为latest,默认策略是Always
启动命令 spec.containers.command
用于在Pod中的容器初始化完毕之后执行一个命令,可以覆盖Dockerfile中的ENTRYPOINT(可配合args使用)。
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-command
namespace: dev
spec:
containers:
- name: nginx # 容器名称
image: nginx:1.17.1 # 容器需要的镜像地址
imagePullPolicy: IfNotPresent # 设置镜像拉取策略
- name: busybox # 容器名称
image: busybox:1.30 # 容器需要的镜像地址
command: ["/bin/sh","-c","touch /tmp/hello.txt;while true;do /bin/echo $(date +%T) >> /tmp/hello.txt;sleep 3;done;"]
环境变量 spec.containers.env
key:value键值对,用于在Pod中的容器设置环境变量。
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-env
namespace: dev
spec:
containers:
- name: nginx # 容器名称
image: nginx:1.17.1 # 容器需要的镜像地址
imagePullPolicy: IfNotPresent # 设置镜像拉取策略
- name: busybox # 容器名称
image: busybox:1.30 # 容器需要的镜像地址
command: ["/bin/sh","-c","touch /tmp/hello.txt;while true;do /bin/echo $(date +%T) >> /tmp/hello.txt;sleep 3;done;"]
env:
- name: "username"
value: "admin"
- name: "password"
value: "123456"
进入容器,输出环境变量:
kubectl exec -it pod-env -n dev -c busybox -it /bin/sh
/ # echo $username
此种方式不推荐,推荐将这些配置单独存储在配置文件中。
端口设置 spec.containers.ports
KIND: Pod
VERSION: v1
RESOURCE: ports <[]Object>
FIELDS:
name <string> # 端口名称,如果指定,必须保证name在pod中是唯一的
containerPort <integer> # 容器要监听的端口(0<x<65536)
hostPort <integer> # 容器要在主机上公开的端口,如果设置,主机上只能运行容器的一个副本(一般省略)
hostIP <string> # 要将外部端口绑定到的主机IP(一般省略)
protocol <string> # 端口协议。必须是UDP、TCP或SCTP。默认为“TCP”
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-ports
namespace: dev
spec:
containers:
- name: nginx # 容器名称
image: nginx:1.17.1 # 容器需要的镜像地址
imagePullPolicy: IfNotPresent # 设置镜像拉取策略
ports:
- name: nginx-port # 端口名称,如果执行,必须保证name在Pod中是唯一的
containerPort: 80 # 容器要监听的端口 (0~65536)
protocol: TCP # 端口协议
可使用podIP:containerPort访问Pod中的容器中
资源配额 spec.containers.resources
resources用于对内存和CPU的资源进行配额,有两个子选项:
(1) limits:容器的最大占用资源,当容器占用资源超过limits时会被终止,并进行重启。
(2) requests:容器需要的最小资源,如果环境资源不够,容器将无法启动(pending)。
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-resoures
namespace: dev
spec:
containers:
- name: nginx # 容器名称
image: nginx:1.17.1 # 容器需要的镜像地址
imagePullPolicy: IfNotPresent # 设置镜像拉取策略
ports: # 端口设置
- name: nginx-port # 端口名称,如果执行,必须保证name在Pod中是唯一的
containerPort: 80 # 容器要监听的端口 (0~65536)
protocol: TCP # 端口协议
resources: # 资源配额
limits: # 限制资源的上限
cpu: "2" # CPU限制,单位是core数,可以为整数或小数。
memory: "10Gi" # 内存限制,可以使用Gi、Mi、G、M等形式
requests: # 限制资源的下限
cpu: "1"
memory: "10Mi"
pod生命周期
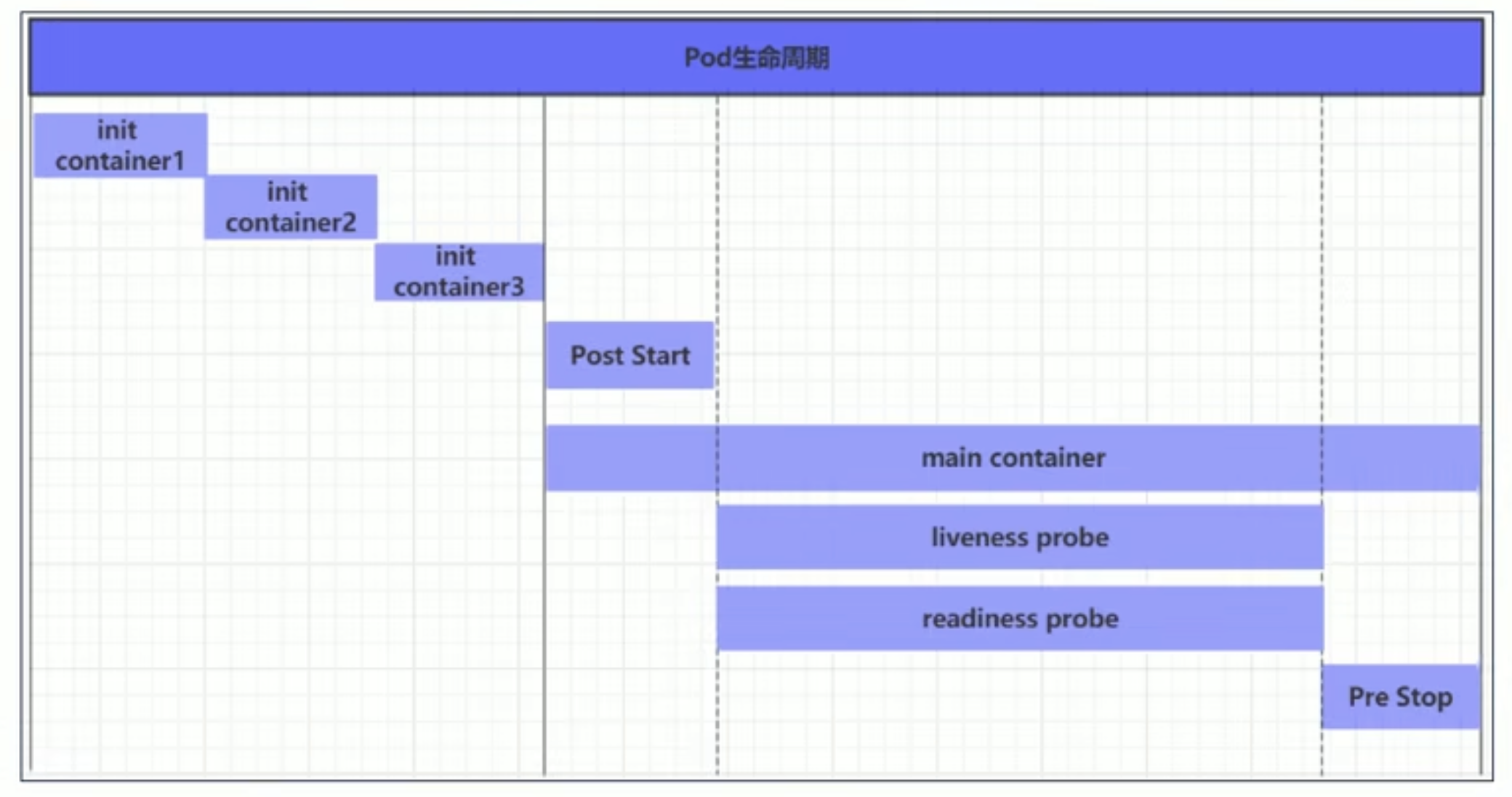
初始化容器 spec.initContainers:
初始化容器是在Pod的主容器启动之前要运行的容器,一般用于使容器满足前置依赖条件。它必须按照定义的顺序执行,并且必须运行成功才能启动主容器。
示例:假设要以主容器来运行Nginx,但是要求在运行Nginx之前要能够连接上MySQL和Redis所在的服务器
apiVersion: v1
kind: Pod
metadata:
name: pod-initcontainer
namespace: dev
spec:
containers: # 容器配置
- name: nginx
image: nginx:1.17.1
imagePullPolicy: IfNotPresent
ports:
- name: nginx-port
containerPort: 80
protocol: TCP
resources:
limits:
cpu: "2"
memory: "10Gi"
requests:
cpu: "1"
memory: "10Mi"
initContainers: # 初始化容器配置
- name: test-mysql
image: busybox:1.30
command: ["sh","-c","until ping 192.168.18.103 -c 1;do echo waiting for mysql ...;sleep 2;done;"]
securityContext:
privileged: true # 使用特权模式运行容器
- name: test-redis
image: busybox:1.30
command: ["sh","-c","until ping 192.168.18.104 -c 1;do echo waiting for redis ...;sleep 2;done;"]
钩子函数 spec.containers.lifecycle.postStart/preStop
kubernetes在主容器启动之后和停止之前提供了两个钩子函数:
- post start:容器创建之后执行,如果失败会重启容器。
- pre stop:容器终止之前执行,执行完成之后容器将成功终止,在其完成之前会阻塞删除容器的操作。
钩子处理器支持的定义动作(新版本有更新?):
-
exec:在容器内执行一次命令
…… lifecycle: postStart: exec: command: - cat - /tmp/healthy …… -
tcpSocket:在当前容器尝试访问指定的socket
…… lifecycle: postStart: tcpSocket: port: 8080 …… -
httpGet:在当前容器中向某url发起HTTP请求
…… lifecycle: postStart: httpGet: path: / #URI地址 port: 80 #端口号 host: 192.168.109.100 #主机地址 scheme: HTTP #支持的协议,http或者https ……
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-hook-exec
namespace: dev
spec:
containers: # 容器配置
- name: nginx
image: nginx:1.17.1
imagePullPolicy: IfNotPresent
ports:
- name: nginx-port
containerPort: 80
protocol: TCP
lifecycle: # 生命周期配置
postStart: # 容器创建之后执行,如果失败会重启容器
exec: # 在容器启动的时候,执行一条命令,修改掉Nginx的首页内容
command: ["/bin/sh","-c","echo postStart ... > /usr/share/nginx/html/index.html"]
preStop: # 容器终止之前执行,执行完成之后容器将成功终止,在其完成之前会阻塞删除容器的操作
exec: # 在容器停止之前停止Nginx的服务
command: ["/usr/sbin/nginx","-s","quit"]
容器探测 spec.containers.livenessProbe/readinessProbe
容器探测用于检测容器中的应用实例是否正常工作。如果实例的状态不符合预期,那么kubernetes就会把该问题实例“摘除”,不承担业务流量。kubernetes提供了两种探针来实现容器探测,分别是:
- liveness probe:存活性探测,用于检测应用实例当前是否处于正常运行状态,如果不是,k8s会重启容器。
- readiness probe:就绪性探测,用于检测应用实例是否可以接受请求,如果不能,k8s不会转发流量(不会重启)。
k8s在1.16版本之后新增了startupProbe探针,用于判断容器内应用程序是否已经启动。如果配置了startupProbe探针,就会先禁止其他的探针,直到startupProbe探针成功为止,一旦成功将不再进行探测。
探针的动作与钩子函数相同,分别是exec、tcpSocket和httpGet。
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-exec
namespace: dev
spec:
containers: # 容器配置
- name: nginx
image: nginx:1.17.1
imagePullPolicy: IfNotPresent
ports:
- name: nginx-port
containerPort: 80
protocol: TCP
livenessProbe: # 存活性探针
exec:
command: ["/bin/cat","/tmp/hello.txt"] # 执行一个查看文件的命令,必须失败,因为根本没有这个文件
探针可配置的其他参数有:
>> kubectl explain pod.spec.containers.livenessProbe
exec
tcpSocket
httpGet
initialDelaySeconds # 容器启动后等待多少秒执行第一次探测
timeoutSeconds # 探测超时时间。默认1秒,最小1秒
periodSeconds # 执行探测的频率。默认是10秒,最小1秒
failureThreshold # 连续探测失败多少次才被认定为失败。默认是3。最小值是1
successThreshold # 连续探测成功多少次才被认定为成功。默认是1
重启策略 spec.restartPolicy
pod的重启策略:
- Always:容器失效时,自动重启该容器,默认值。
- OnFailure:容器终止运行且退出码不为0时重启。
- Never:不论状态如何,都不重启该容器。
重启策略适用于Pod对象中的所有容器,首次需要重启的容器将立即进行重启,随后再次重启的操作将由kubelet延迟一段时间后进行,且反复的重启操作的延迟时长以此为10s、20s、40s、80s、160s和300s,300s是最大的延迟时长。
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-restart-policy
namespace: dev
spec:
containers: # 容器配置
- name: nginx
image: nginx:1.17.1
imagePullPolicy: IfNotPresent
ports:
- name: nginx-port
containerPort: 80
protocol: TCP
livenessProbe: # 存活性探测
httpGet:
port: 80
path: /hello
host: 127.0.0.1
scheme: HTTP
restartPolicy: Never # 重启策略
pod调度
四种pod调度方式:
(1)自动调度:运行在哪个Node节点上由Scheduler经过的算法计算得出(默认)
(2)定向调度:NodeName、NodeSelector
(3)亲和性调度:NodeAffinity、PodAffinity、PodAntiAffinity
(4)污点(容忍)调度:Taints、Toleration
定向调度
配置spec.nodeName或spec.nodeSelector从而将Pod调度到期望的Node节点上。
这里的调度是强制的,即使要调度的目标Node不存在,也会向上面进行调度,但Pod运行会失败。
nodeName用于根据node name将Pod调度到指定的Node上。示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-nodename
namespace: dev
spec:
containers: # 容器配置
- name: nginx
image: nginx:1.17.1
imagePullPolicy: IfNotPresent
ports:
- name: nginx-port
containerPort: 80
protocol: TCP
nodeName: k8s-node1 # 指定调度到k8s-node1节点上
nodeSelector用于将Pod调度到添加了指定label的Node上,它是通过kubernetes的label-selector机制实现的。示例:
kubectl label node k8s-node1 nodeenv=pro
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeselector
namespace: dev
spec:
containers: # 容器配置
- name: nginx
image: nginx:1.17.1
imagePullPolicy: IfNotPresent
ports:
- name: nginx-port
containerPort: 80
protocol: TCP
nodeSelector:
nodeenv: pro # 指定调度到具有nodeenv=pro的Node节点上
亲和性调度
定向调度的问题:强制调度,如果没有满足条件的Node,Pod将不会被运行
基于上面的问题,kubernetes还提供了一种亲和性调度(Affinity)。它在nodeSelector的基础之上进行了扩展,可以优先选择满足条件的Node进行调度,如果没有,也可以调度到不满足条件的节点上,使得调度更加灵活。
Affinity主要分为三类:
- nodeAffinity(node亲和性):以Node为目标,解决Pod可以调度到哪些Node的问题。
- podAffinity(pod亲和性):以Pod为目标,解决Pod可以和那些已存在的Pod部署在同一个拓扑域中的问题。
- podAntiAffinity(pod反亲和性):以Pod为目标,解决Pod不能和那些已经存在的Pod部署在同一拓扑域中的问题。
关于亲和性和反亲和性的使用场景的说明:
- 亲和性:如果两个应用频繁交互,那么就有必要利用亲和性让两个应用尽可能的靠近,这样可以较少因网络通信而带来的性能损耗。
- 反亲和性:当应用采用多副本部署的时候,那么就有必要利用反亲和性让各个应用实例打散分布在各个Node上,这样可以提高服务的高可用性。
nodeAffinity包含requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution两种:
pod.spec.affinity.nodeAffinity
requiredDuringSchedulingIgnoredDuringExecution Node必须满足指定的所有规则才可以,相当于硬限制
nodeSelectorTerms
matchFields 按node字段选择
matchExpressions 按node标签选择(推荐)
key 键
values 值
operator 关系符 支持Exists, DoesNotExist, In, NotIn, Gt, Lt
preferredDuringSchedulingIgnoredDuringExecution 优先调度到满足指定的规则的Node,相当于软限制 (倾向)
preference
matchFields 按node字段选择
matchExpressions 按node标签选择(推荐)
key 键
values 值
operator 关系符 支持In, NotIn, Exists, DoesNotExist, Gt, Lt
weight 倾向权重,在范围1-100。
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeaffinity-preferred
namespace: dev
spec:
containers: # 容器配置
- name: nginx
image: nginx:1.17.1
imagePullPolicy: IfNotPresent
ports:
- name: nginx-port
containerPort: 80
protocol: TCP
affinity: # 亲和性配置
nodeAffinity: # node亲和性配置
preferredDuringSchedulingIgnoredDuringExecution: # 优先调度到满足指定的规则的Node,相当于软限制 (倾向)
- preference: # 一个节点选择器项,与相应的权重相关联
matchExpressions:
- key: nodeenv # 优先匹配存在标签的key为nodeenv的节点,并且value是"xxx"或"yyy"的节点
operator: In
values:
- "xxx"
- "yyy"
weight: 1
nodeAffinity的注意事项:
-
如果同时定义了nodeSelector和nodeAffinity,那么必须两个条件都满足,Pod才能运行在指定的Node上。
-
如果nodeAffinity指定了多个nodeSelectorTerms,那么只需要其中一个能够匹配成功即可。
-
如果一个nodeSelectorTerm中有多个matchExpressions,则一个节点必须满足所有的才能匹配成功。
-
如果一个Pod所在的Node在Pod运行期间其标签发生了改变,不再符合该Pod的nodeAffinity的要求,则系统将忽略此变化。
PodAffinity与podAntiAffinity(以PodAffinity为例):
pod.spec.affinity.podAffinity
requiredDuringSchedulingIgnoredDuringExecution 硬限制
namespaces 指定参照pod的namespace
topologyKey 指定调度作用域
labelSelector 标签选择器
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持In, NotIn, Exists, DoesNotExist.
matchLabels 指多个matchExpressions映射的内容
preferredDuringSchedulingIgnoredDuringExecution 软限制
podAffinityTerm 选项
namespaces
topologyKey
labelSelector
matchExpressions
key 键
values 值
operator
matchLabels
weight 倾向权重,在范围1-1
topologyKey用于指定调度的作用域,例如:
-
如果指定为kubernetes.io/hostname,那就是以Node节点为区分范围。
-
如果指定为beta.kubernetes.io/os,则以Node节点的操作系统类型来区分。
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-podaffinity-requred
namespace: dev
spec:
containers: # 容器配置
- name: nginx
image: nginx:1.17.1
imagePullPolicy: IfNotPresent
ports:
- name: nginx-port
containerPort: 80
protocol: TCP
affinity: # 亲和性配置
podAffinity: # Pod亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬限制
- labelSelector:
matchExpressions: # 该Pod必须和拥有标签podenv=xxx或者podenv=yyy的Pod在同一个Node上
- key: podenv
operator: In
values:
- "xxx"
- "yyy"
topologyKey: kubernetes.io/hostname
污点(Taints)和容忍(Toleration)
在Node的角度上,通过在Node上添加污点(拒绝策略),来决定是否接受Pod调度过来。
污点的格式:key=value:effect(似乎可以没有value,只有key和effect)
key和value是污点的标签,effect描述污点的作用,支持如下三个选项:
- PreferNoSchedule
- NoSchedule(通常Master节点会有一个默认NoSchedule污点)
- NoExecute

# 设置污点
kubectl taint node xxx key=value:effect
# 删除污点
kubectl taint node xxx key:effect-
# 删除所有污点
kubectl taint node xxx key-
# 查看指定节点上的污点
kubectl describe node xxx
# 列出所有节点的污点
kubectl get nodes -o json | jq '.items[].spec'
kubectl get nodes -o json | jq '.items[].spec.taints'
对应的,容忍相当于忽略策略。Node通过污点拒绝Pod调度上去,Pod通过容忍忽略拒绝。
容忍配置:
kubectl explain pod.spec.tolerations
FIELDS:
key # 要容忍的污点的键,空意味着匹配所有的键
value # 要容忍的污点的值
operator # key-value的运算符,支持Equal和Exists(默认,Exists只匹配key是否存在)
effect # 对应污点的effect,空意味着匹配所有影响
tolerationSeconds # 容忍时间, 当effect为NoExecute时生效,表示pod在Node上的停留时间
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-toleration
namespace: dev
spec:
containers: # 容器配置
- name: nginx
image: nginx:1.17.1
imagePullPolicy: IfNotPresent
ports:
- name: nginx-port
containerPort: 80
protocol: TCP
tolerations: # 容忍
- key: "tag" # 要容忍的污点的key
operator: Equal # 操作符
value: "pro" # 要容忍的污点的value
effect: NoExecute # 添加容忍的规则,这里必须和标记的污点规则相同
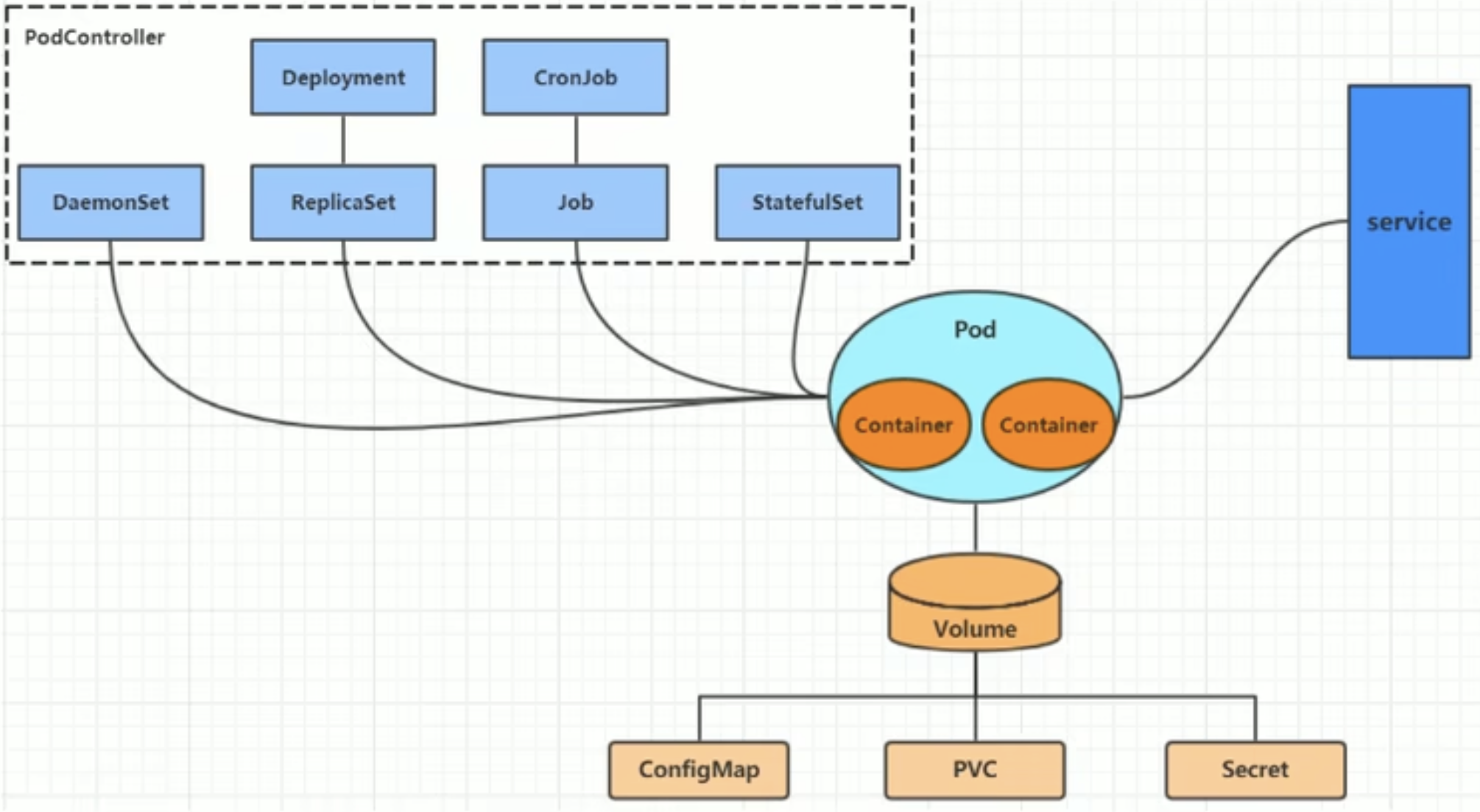
6 Pod控制器
在kubernetes中,Pod的创建方式有两类:
- 自主式Pod:删除后不会重建。
- 控制器创建Pod:控制器可以指定Pod数量,保证每一个Pod处于用户期望的状态。如果Pod在运行中出现故障,控制器会基于指定的策略重启或重建Pod。
常见Pod控制器类型:
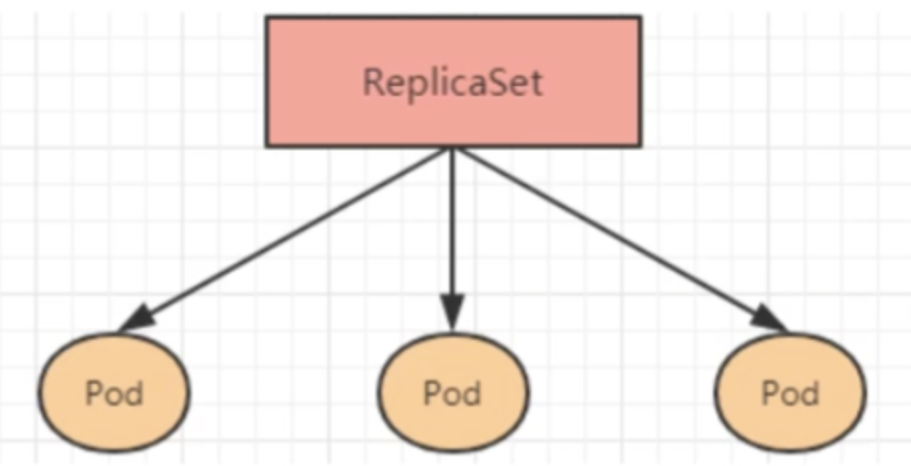
- ReplicaSet:保证指定数量的Pod运行,支持Pod数量变更。
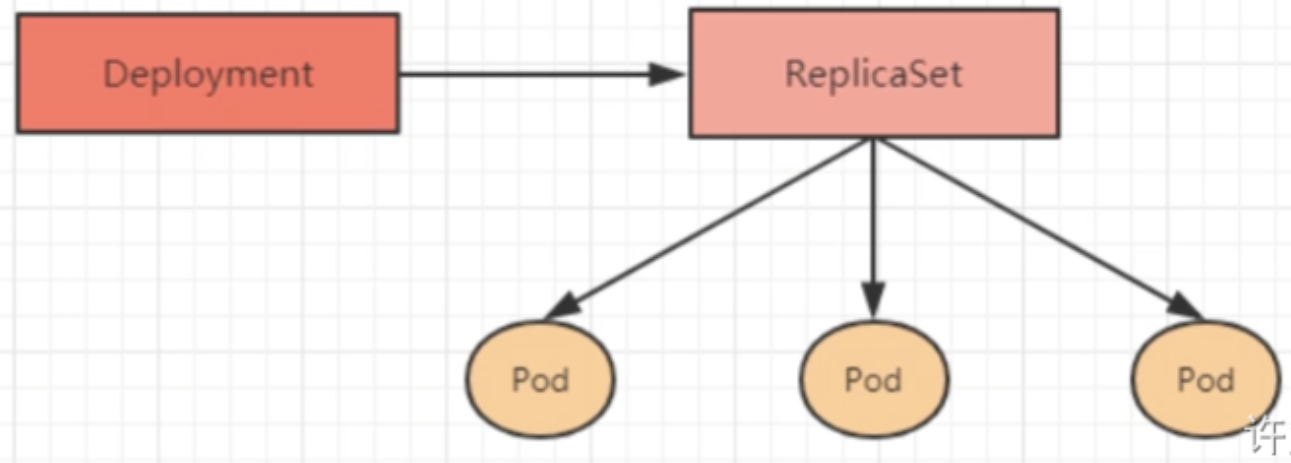
- Deployment:通过控制ReplicaSet来控制Pod,并支持滚动升级、版本回退。
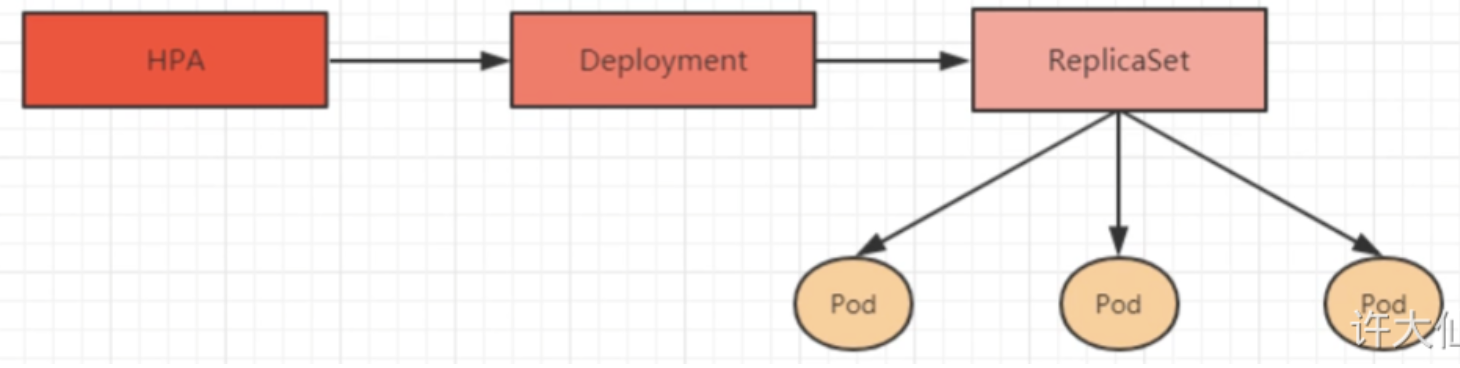
- Horizontal Pod Autoscaler:可以根据集群负载自动调整Pod的数量,实现削峰填谷。
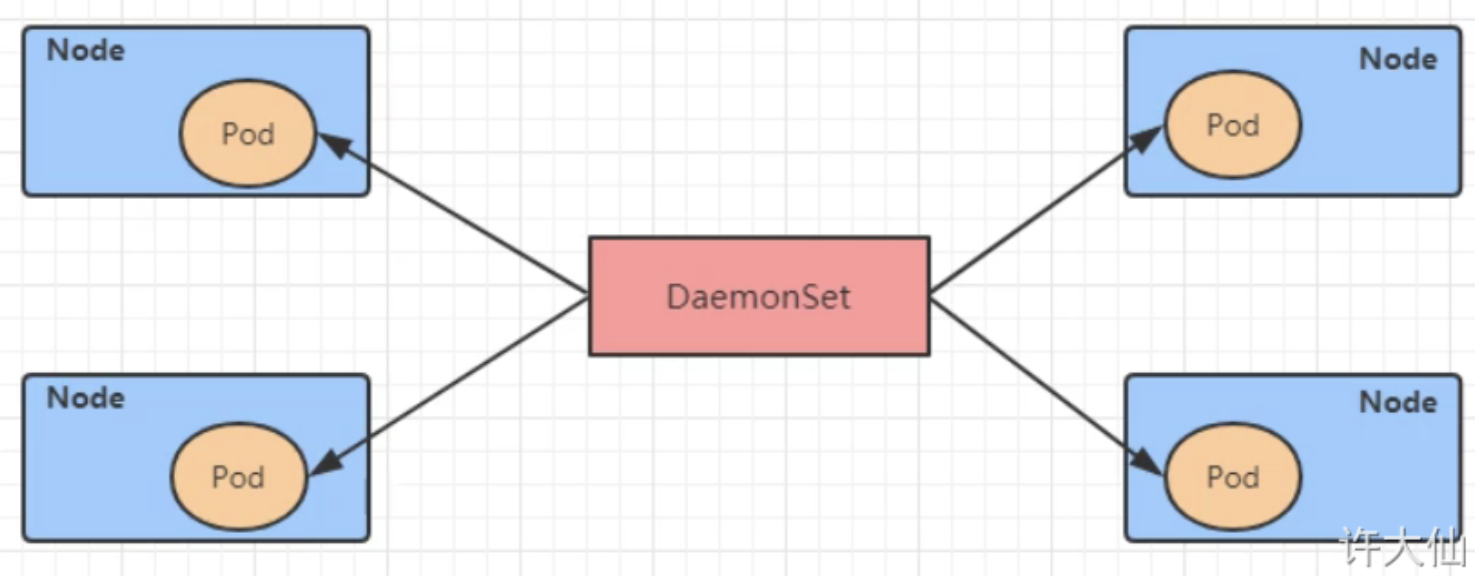
- DaemonSet:在集群中的指定Node上都运行一个副本,一般用于守护进程类的任务。
- Job:创建执行一次性任务的Pod。
- CronJob:创建执行周期性的任务的Pod。
- StatefulSet:管理有状态的应用。
ReplicaSet
yaml:
apiVersion: apps/v1 # 版本号
kind: ReplicaSet # 类型
metadata: # 元数据
name: # rs名称
namespace: # 所属命名空间
labels: #标签
controller: rs
spec: # 详情描述
replicas: 3 # 副本数量
selector: # 选择器,通过它指定该控制器管理哪些po
matchLabels: # Labels匹配规则,与template中的label对应
app: nginx-pod
matchExpressions: # Expressions匹配规则,可省略
- {key: app, operator: In, values: [nginx-pod]}
template: # 模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
扩缩容:
# 方法1: 编辑yaml中的spec.replicas
kubectl edit rs xxx -n ns
kubectl apply -f rs.yaml
# 方法2: 使用scale命令
kubectl scale rs xxx --replicas=2 -n ns
Deployment
Deployment通过管理ReplicaSet来管理Pod。在ReplicaSet的基础上,Deployment额外支持:
- 发布的停止、继续
- 版本滚动更新和版本回退
yaml:
apiVersion: apps/v1 # 版本号
kind: Deployment # 类型
metadata: # 元数据
name: # rs名称
namespace: # 所属命名空间
labels: #标签
controller: deploy
spec: # 详情描述
replicas: 3 # 副本数量
revisionHistoryLimit: 3 # 保留历史版本,默认为10
paused: false # 暂停部署,默认是false
progressDeadlineSeconds: 600 # 部署超时时间(s),默认是600
strategy: # 策略
type: RollingUpdate # 滚动更新策略
rollingUpdate: # 滚动更新
maxSurge: 30% # 最大额外可以存在的副本数,可以为百分比,也可以为整数 maxUnavailable: 30% # 最大不可用状态的 Pod 的最大值,可以为百分比,也可以为整数
selector: # 选择器,通过它指定该控制器管理哪些pod
matchLabels: # Labels匹配规则,与template中的label对应
app: nginx-pod
matchExpressions: # Expressions匹配规则,可省略
- {key: app, operator: In, values: [nginx-pod]}
template: # 模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
创建Deployment
示例:
apiVersion: apps/v1 # 版本号
kind: Deployment # 类型
metadata: # 元数据
name: pc-deployment # deployment的名称
namespace: dev # 命名类型
spec: # 详细描述
replicas: 3 # 副本数量
selector: # 选择器,通过它指定该控制器可以管理哪些Pod
matchLabels: # Labels匹配规则
app: nginx-pod
template: # 模块 当副本数据不足的时候,会根据下面的模板创建Pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx # 容器名称
image: nginx:1.17.1 # 容器需要的镜像地址
ports:
- containerPort: 80 # 容器所监听的端口
kubectl create -f pc-deployment.yaml
扩缩容
# 方法1: 编辑yaml中的spec.replicas
kubectl edit deployment pc-deployment -n ns
# 方法2: 使用scale命令
kubectl scale deploy pc-deployment --replicas=5 -n ns
镜像更新
Deployment支持两种镜像更新的策略——重建更新和滚动更新(默认),可以通过spec.strategy进行配置:
strategy:
type:
Recreate # 在创建出新的Pod之前会先杀掉所有已经存在的Pod
RollingUpdate #滚动更新,就是杀死一部分,就启动一部分,在更新过程中,存在两个版本的Pod
rollingUpdate: # 用于为rollingUpdate设置参数,支持两个属性:
maxUnavailable:25% # 用来指定在升级过程中不可用的Pod的最大数量,默认为25%。
maxSurge:25% # 用来指定在升级过程中可以超过期望的Pod的最大数量,默认为25%。
重建更新(Recreate):
示例:
apiVersion: apps/v1 # 版本号
kind: Deployment # 类型
metadata: # 元数据
name: pc-deployment # deployment的名称
namespace: dev # 命名类型
spec: # 详细描述
replicas: 3 # 副本数量
strategy: # 镜像更新策略
type: Recreate # Recreate:在创建出新的Pod之前会先杀掉所有已经存在的Pod
selector: # 选择器,通过它指定该控制器可以管理哪些Pod
matchLabels: # Labels匹配规则
app: nginx-pod
template: # 模块 当副本数据不足的时候,会根据下面的模板创建Pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx # 容器名称
image: nginx:1.17.1 # 容器需要的镜像地址
ports:
- containerPort: 80 # 容器所监听的端口
升级镜像:
kubectl set image deployment pc-deployment nginx=nginx:1.17.2 -n dev
监控升级过程:
kubectl get pod -n dev -w
Deployment会在创建出新的Pod之前终止所有已经存在的Pod。
滚动更新(RollingUpdate):
示例:
apiVersion: apps/v1 # 版本号
kind: Deployment # 类型
metadata: # 元数据
name: pc-deployment # deployment的名称
namespace: dev # 命名类型
spec: # 详细描述
replicas: 3 # 副本数量
strategy: # 镜像更新策略
type: RollingUpdate # RollingUpdate:滚动更新,就是杀死一部分,就启动一部分,在更新过程中,存在两个版本的Pod
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
selector: # 选择器,通过它指定该控制器可以管理哪些Pod
matchLabels: # Labels匹配规则
app: nginx-pod
template: # 模块 当副本数据不足的时候,会根据下面的模板创建Pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx # 容器名称
image: nginx:1.17.1 # 容器需要的镜像地址
ports:
- containerPort: 80 # 容器所监听的端口
Deployment会停止一个旧版本并启动一个新版本,更新过程中同时存在两个版本。
镜像更新中rs的变化:在更新后原来的rs依旧存在,只是Pod的数量变为0,新创建的rs中Pod的数量为3。这是deployment能够进行版本回退的原因。
版本回退
rollout操作:
kubetl rollout {opt} deploy pc-deployment
# status 显示当前升级的状态
# history 显示升级历史记录
# undo 回滚到上一级版本 (可以使用--to-revision回滚到指定的版本)
# pause 暂停版本升级过程
# resume 继续已经暂停的版本升级过程
# restart 重启版本升级过程
查看当前升级版本的状态:
>> kubectl rollout status deployment pc-deployment -n ns
deployment "pc-deployment" successfully rolled out
查看升级历史记录:
>> kubectl rollout history deployment pc-deployment -n ns
deployment.apps/pc-deployment
REVISION CHANGE-CAUSE
1 <none> (需要在启动时加--record才能显示具体记录)
2 <none>
3 <none>
版本回退:
# 可以使用-to-revision=1回退到1版本,如果省略这个选项,就是回退到上个版本,即2版本
>> kubectl rollout undo deployment pc-deployment --to-revision=1 -n ns
deployment "pc-deployment" rolled back
Horizontal Pod Autoscaler(HPA)
HPA可以获取每个Pod的利用率(负载变化情况),与HPA中定义的指标对比,计算出需要伸缩的具体值,实现Pod数量的自适应调整。
hpa示例:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: pc-hpa
namespace: dev
spec:
minReplicas: 1 # 最小Pod数量
maxReplicas: 10 # 最大Pod数量
targetCPUUtilizationPercentage: 30 # CPU使用率指标 - 30%
scaleTargetRef: # 指定要控制的Nginx的信息
apiVersion: apps/v1
kind: Deployment
name: nginx
kubectl create -f pc-hpa.yaml
kubectl get hpa -n dev
准备工作:安装metrics-server
(1)下载 metrics-server 官方的部署 yaml,目前更新到0.6.4
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
(2)修改components.yaml
metrics-server 会请求每台节点的 kubelet 接口来获取监控数据,接口通过 HTTPS 暴露,但 Kubernetes 节点的 kubelet 使用的是自签证书,若 metrics-server 直接请求 kubelet 接口,将产生证书校验失败的错误,因此需要在 components.yaml 文件中加上 –kubelet-insecure-tls 启动参数。
containers:
- args:
- --cert-dir=/tmp
- --secure-port=443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls # 加上该启动参数
image: registry.k8s.io/metrics-server/metrics-server:v0.6.4 # 需要代理!!!
(3)部署 metrics-server
kubectl apply -f components.yaml
检查pod 状态:
kubectl get pod -n kube-system | grep metrics-server
检查pod资源占用:
kubectl top nodes
DaemonSet(DS)
DaemonSet可以保证集群中的每一台(或指定)节点上都运行一个pod副本,一般适用于日志收集、节点监控等场景。每向cluster中添加一个node,指定的Pod副本也将添加到该node上。
yaml(与前面类似):
apiVersion: apps/v1 # 版本号
kind: DaemonSet # 类型
metadata: # 元数据
name: # 名称
namespace: #命名空间
labels: #标签
controller: daemonset
spec: # 详情描述
revisionHistoryLimit: 3 # 保留历史版本
updateStrategy: # 更新策略
type: RollingUpdate # 滚动更新策略
rollingUpdate: # 滚动更新
maxUnavailable: 1 # 最大不可用状态的Pod的最大值,可用为百分比,也可以为整数
selector: # 选择器,通过它指定该控制器管理那些Pod
matchLabels: # Labels匹配规则
app: nginx-pod
matchExpressions: # Expressions匹配规则
- key: app
operator: In
values:
- nginx-pod
template: # 模板,当副本数量不足时,会根据下面的模板创建Pod模板
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
Job
Job主要用于负责批量处理短暂的一次性任务。任务执行会创建pod,执行完毕pod的状态变为completed
yaml:
apiVersion: batch/v1 # 版本号
kind: Job # 类型
metadata: # 元数据
name: # 名称
namespace: #命名空间
labels: # 标签
controller: job
spec: # 详情描述
completions: 1 # 指定Job需要成功运行Pod的总次数,默认为1
parallelism: 1 # 指定Job在任一时刻应该并发运行Pod的数量,默认为1
activeDeadlineSeconds: 30 # 指定Job可以运行的时间期限,超过时间还没结束,系统将会尝试进行终止
backoffLimit: 6 # 指定Job失败后进行重试的次数,默认为6
manualSelector: true # 是否可以使用selector选择器选择Pod,默认为false
selector: # 选择器,通过它指定该控制器管理那些Pod
matchLabels: # Labels匹配规则
app: counter-pod
matchExpressions: # Expressions匹配规则
- key: app
operator: In
values:
- counter-pod
template: # 模板,当副本数量不足时,会根据下面的模板创建Pod模板
metadata:
labels:
app: counter-pod
spec:
restartPolicy: Never # 重启策略只能设置为Never或OnFailure
containers:
- name: counter
image: busybox:1.30
command: ["/bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1;do echo $i;sleep 20;done"]
关于模板中的重启策略的说明:
-
如果设置为OnFailure,则Job会在Pod出现故障的时候重启容器,而不是创建Pod,failed次数不变。
-
如果设置为Never,则Job会在Pod出现故障的时候创建新的Pod,并且故障Pod不会消失,也不会重启,failed次数+1。
-
如果指定为Always的话,就意味着一直重启,意味着Pod任务会重复执行,这和Job的定义冲突,所以不能设置为Always。
CronJob(CJ)
CronJob通过管理Job,实现周期性执行Job。
yaml:
apiVersion: batch/v1beta1 # 版本号
kind: CronJob # 类型
metadata: # 元数据
name: # 名称
namespace: #命名空间
labels:
controller: cronjob
spec: # 详情描述
schedule: # cron格式的作业调度运行时间点,用于控制任务任务时间执行
concurrencyPolicy: # 并发执行策略
failedJobsHistoryLimit: # 为失败的任务执行保留的历史记录数,默认为1
successfulJobsHistoryLimit: # 为成功的任务执行保留的历史记录数,默认为3
jobTemplate: # job控制器模板,用于为cronjob控制器生成job对象,下面其实就是job的定义
metadata: {}
spec:
completions: 1 # 指定Job需要成功运行Pod的总次数,默认为1
parallelism: 1 # 指定Job在任一时刻应该并发运行Pod的数量,默认为1
activeDeadlineSeconds: 30 # 指定Job可以运行的时间期限,超过时间还没结束,系统将会尝试进行终止
backoffLimit: 6 # 指定Job失败后进行重试的次数,默认为6
template: # 模板,当副本数量不足时,会根据下面的模板创建Pod模板
spec:
restartPolicy: Never # 重启策略只能设置为Never或OnFailure
containers:
- name: counter
image: busybox:1.30
command: [ "/bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1;do echo $i;sleep 20;done" ]
schedule:cron表达式,用于指定任务的执行时间。
- */1 * * * *:表示分钟 小时 日 月份 星期。
- 分钟的值从0到59。
- 小时的值从0到23。
- 日的值从1到31。
- 月的值从1到12。
- 星期的值从0到6,0表示星期日。
- 多个时间可以用逗号隔开,范围可以用连字符给出:* 可以作为通配符,/表示每…
concurrencyPolicy:并发执行策略
- Allow:运行Job并发运行(默认)。
- Forbid:禁止并发运行,如果上一次运行尚未完成,则跳过下一次运行。
- Replace:替换,取消当前正在运行的作业并使用新作业替换它。
7 Service
Service基础
- Service会对提供同一个服务的多个Pod进行聚合,并且提供一个统一的入口地址,通过访问Service的入口地址访问对应的Pod服务。
- Service在很多情况下只是一个概念,真正起作用的是Node上的kube-proxy服务进程。
- 四层路由。
yaml配置:
apiVersion: v1 # 版本
kind: Service # 类型
metadata: # 元数据
name: # 资源名称
namespace: # 命名空间
spec:
selector: # 标签选择器,用于确定当前Service代理那些Pod
app: nginx
type: NodePort # Service的类型,指定Service的访问方式
clusterIP: # 虚拟服务的IP地址
sessionAffinity: # session亲和性,支持ClientIP、None两个选项,默认值为None
ports: # 端口信息
- port: 8080 # Service端口
protocol: TCP # 协议
targetPort : # Pod端口
nodePort: # 主机端口
spec.type的说明:
- ClusterIP:默认值,它是kubernetes系统自动分配的虚拟IP,只能在集群内部访问。
- NodePort:将Service通过指定的Node上的端口暴露给外部,可以在集群外部访问服务。
- LoadBalancer:使用外接负载均衡器完成到服务的负载分发,注意此模式需要外部云环境的支持。
- ExternalName:把集群外部的服务引入集群内部。
不同类型Service示例
ClusterIP
apiVersion: v1
kind: Service
metadata:
name: service-clusterip
namespace: dev
spec:
selector:
app: nginx-pod
clusterIP: 10.97.97.97 # service的IP地址,如果不写,默认会生成一个
type: ClusterIP
ports:
- port: 80 # Service的端口
targetPort: 80 # Pod的端口
可以在集群内部访问10.97.97.97:80。
HeadLiness
设置clusterIP: None
apiVersion: v1
kind: Service
metadata:
name: service-headliness
namespace: dev
spec:
selector:
app: nginx-pod
clusterIP: None # 将clusterIP设置为None,即可创建headliness Service
type: ClusterIP
ports:
- port: 80 # Service的端口
targetPort: 80 # Pod的端口
这类Service不会分配Cluster IP,如果想要访问Service,只能通过Service的域名进行查询。
NodePort
NodePort的工作原理是将Service的端口映射到Node的一个端口上,通过NodeIP:NodePort访问Service。
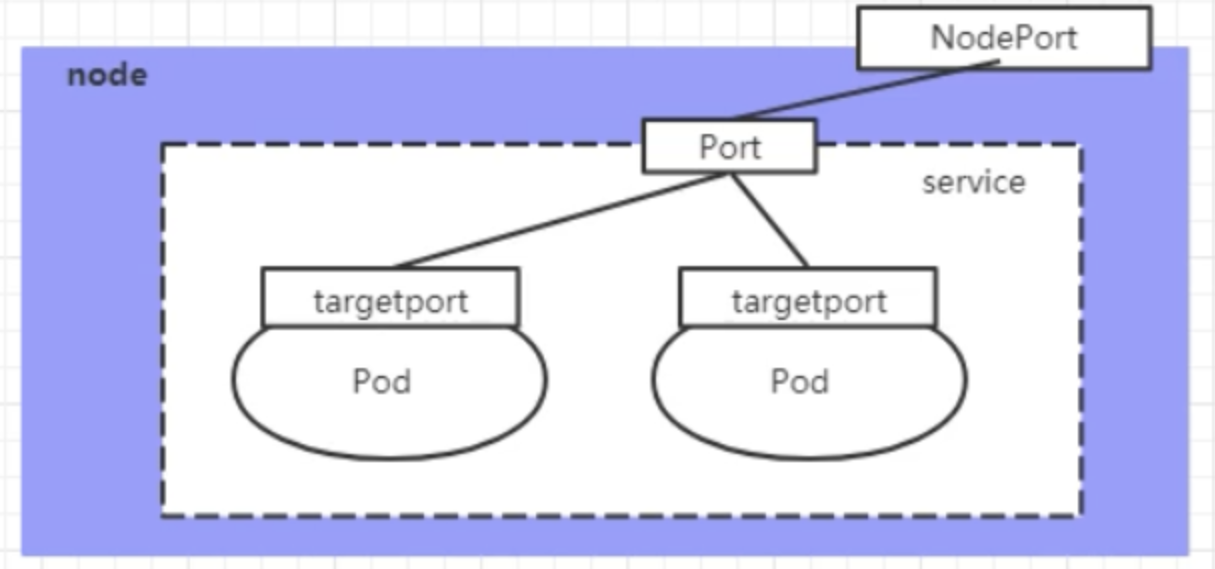
apiVersion: v1
kind: Service
metadata:
name: service-nodeport
namespace: dev
spec:
selector:
app: nginx-pod
type: NodePort # Service类型为NodePort
ports:
- port: 80 # Service的端口
targetPort: 80 # Pod的端口
nodePort: 30002 # 指定绑定的node的端口(默认取值范围是30000~32767),如果不指定,会默认分配
Ingress
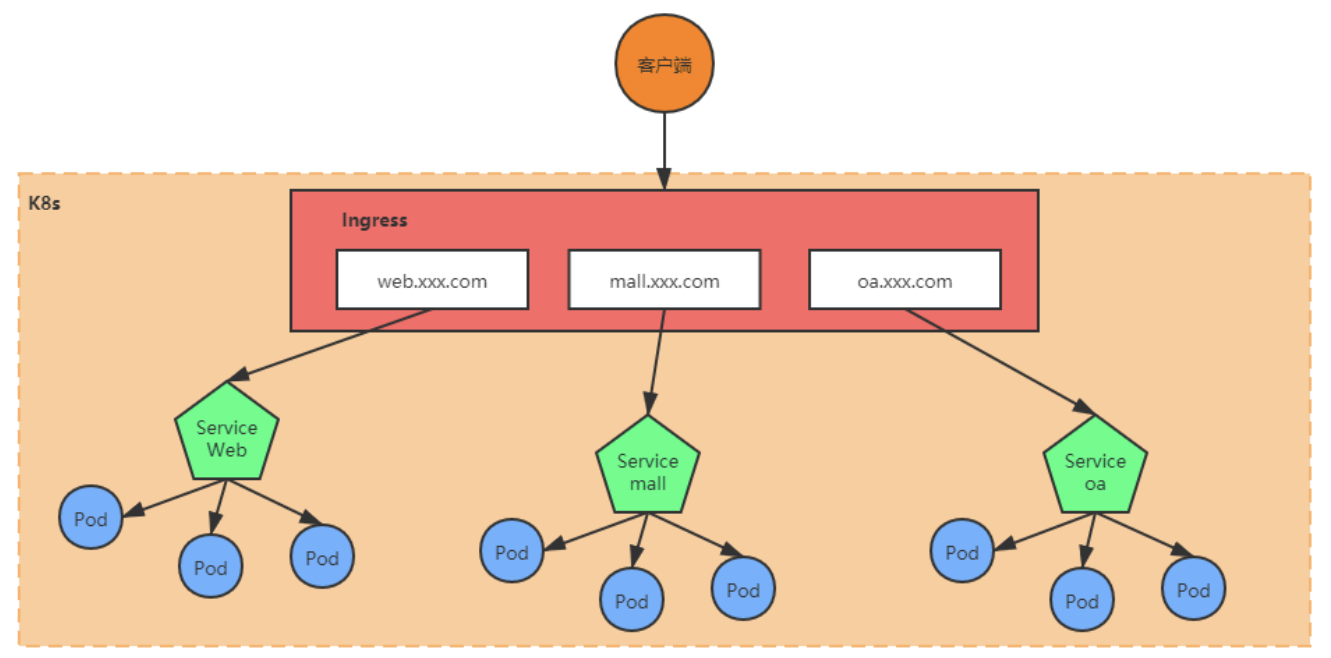
Ingress相当于一个七层的负载均衡器,是kubernetes对反向代理的一个抽象,它的工作原理类似于Nginx,可以理解为Ingress里面建立了诸多映射规则,Ingress Controller通过监听这些配置规则并转化为Nginx的反向代理配置,然后对外提供服务。
- Ingress:kubernetes中的一个对象,定义了请求如何转发到Service的规则。
- Ingress Controller:具体实现反向代理及负载均衡的程序,对Ingress定义的规则进行解析,根据配置的规则来实现请求转发,实现的方式有Nginx、Contour、Haproxy等。
安装ingress controller -> contour
>> kubectl get service -n projectcontour
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
contour ClusterIP 10.96.211.116 <none> 8001/TCP 2d6h
envoy LoadBalancer 10.96.116.49 <pending> 80:31655/TCP,443:30244/TCP 2d6h
这里容器内的80端口(http)映射到cluster的31655端口,容器内的443端口(https)映射到cluster的30244端口。
Ingress http示例:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-http
namespace: dev
spec:
rules:
- host: nginx.com
http:
paths:
- path: /
backend:
serviceName: nginx-service
servicePort: 80
- host: tomcat.com
http:
paths:
- path: /
backend:
serviceName: tomcat-service
servicePort: 8080
Ingress https示例:
kubectl create secret tls tls-secret --key tls.key --cert tls.crt
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-https
namespace: dev
spec:
tls:
- hosts:
- nginx.com
- tomcat.com
secretName: tls-secret # 指定秘钥
rules:
- host: nginx.com
http:
paths:
- path: /
backend:
serviceName: nginx-service
servicePort: 80
- host: tomcat.com
http:
paths:
- path: /
backend:
serviceName: tomcat-service
servicePort: 8080
8 数据存储
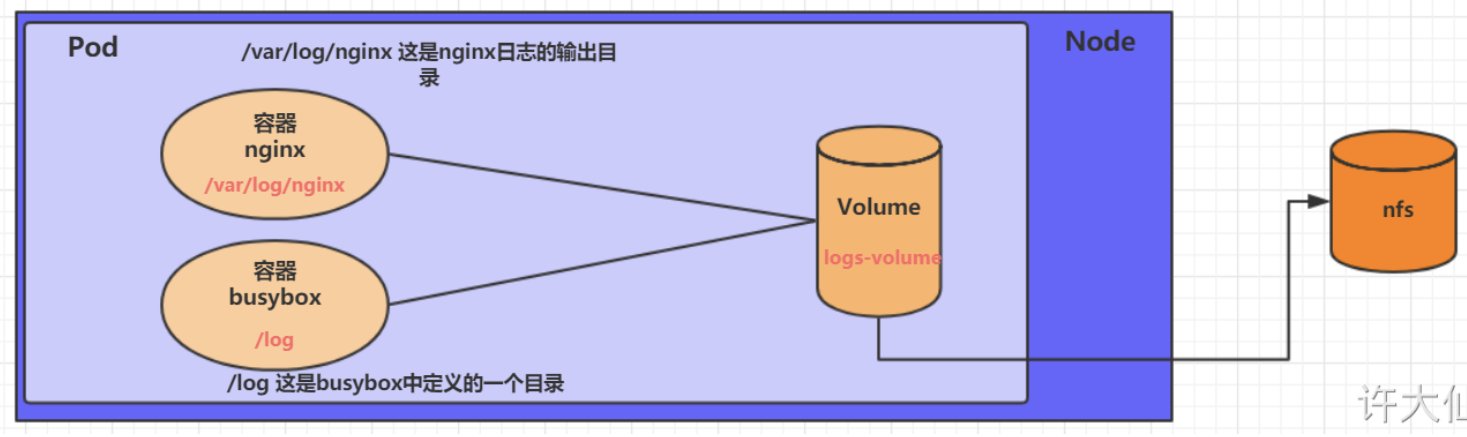
为了持久化保存容器中的数据,kubernetes引入了Volume的概念。
Volume是Pod中能够被多个容器访问的共享目录,它被定义在Pod上,然后被一个Pod里面的多个容器挂载到具体的文件目录下,kubernetes通过Volume实现同一个Pod中不同容器之间的数据共享和持久化。
kubernetes的Volume支持多种类型,比较常见的有下面的几个:
- 基本存储:EmptyDir、HostPath、NFS
- 高级存储:PV、PVC
- 配置存储:ConfigMap、Secret
基本存储
EmptyDir
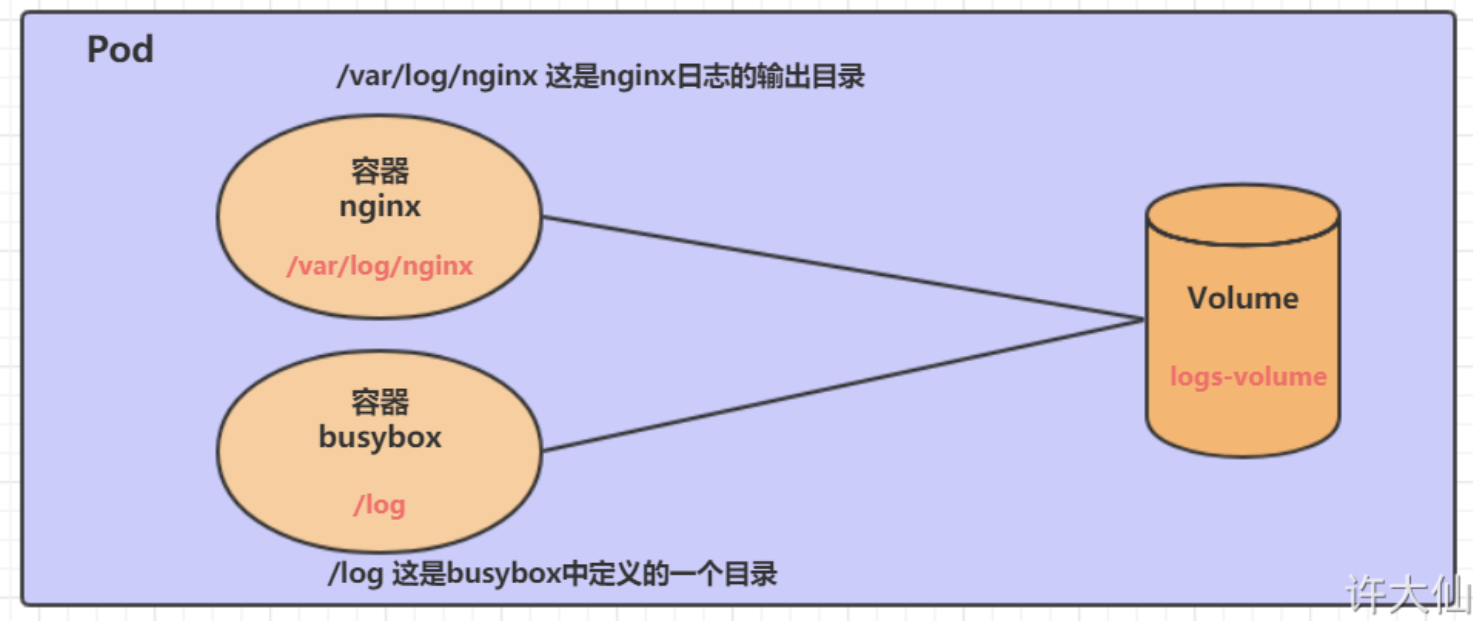
EmptyDir创建在节点临时存储中,在Pod被分配到Node时创建。当Pod销毁时,EmptyDir中的数据也会被永久删除。
EmptyDir一般用于:
- 临时空间,例如用于某些应用程序运行时所需的临时目录。
- 一个容器需要从另一个容器中获取数据的目录(多容器共享目录)。
示例:
apiVersion: v1
kind: Pod
metadata:
name: volume-emptydir
namespace: dev
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts: # 将logs-volume挂载到nginx容器中对应的目录,该目录为/var/log/nginx
- name: logs-volume
mountPath: /var/log/nginx
- name: busybox
image: busybox
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","tail -f /logs/access.log"] # 初始命令,动态读取指定文件
volumeMounts: # 将logs-volume挂载到busybox容器中的对应目录,该目录为/logs
- name: logs-volume
mountPath: /logs
volumes: # 声明volume,name为logs-volume,类型为emptyDir
- name: logs-volume
emptyDir: {}
HostPath
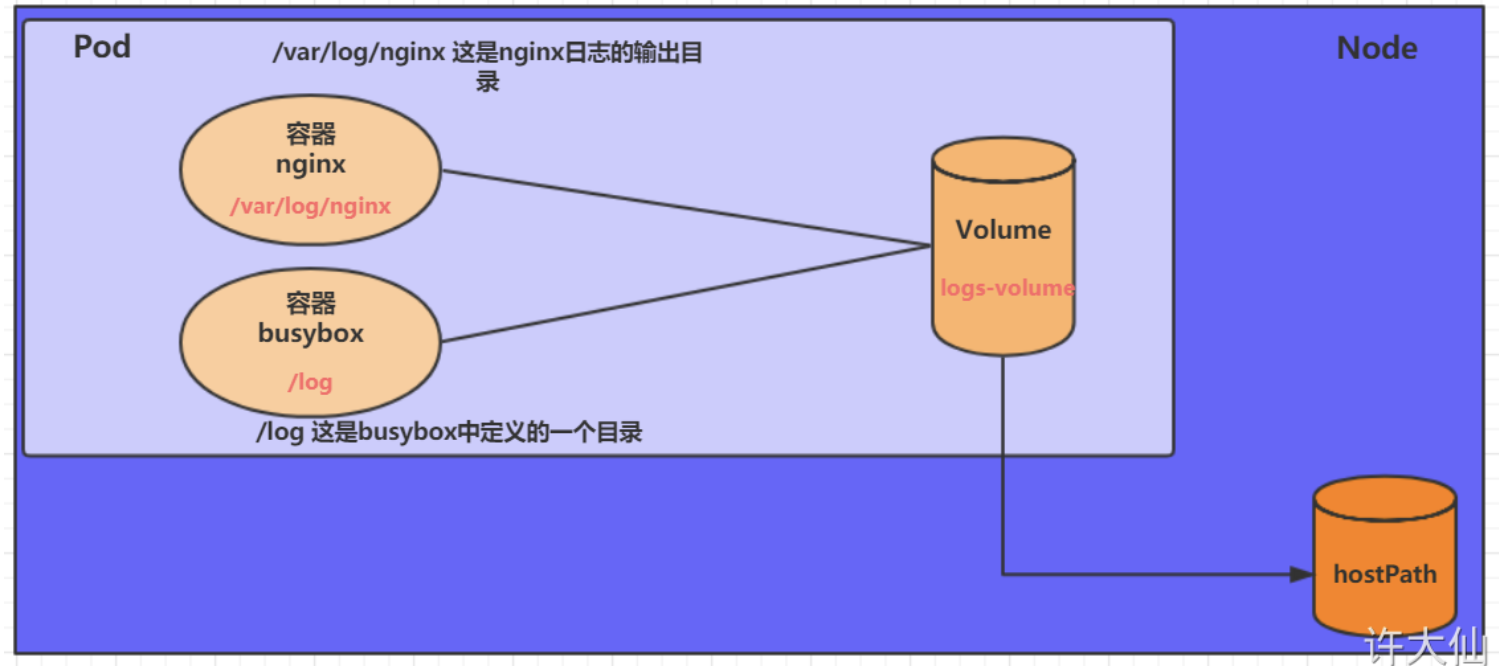
HostPath将Node主机中的一个实际目录挂载到Pod中,即使Pod销毁,数据依旧可以保存在Node主机上。
同样,如果在此目录中创建文件,容器中也是可以看到的。
示例:
apiVersion: v1
kind: Pod
metadata:
name: volume-hostpath
namespace: dev
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts: # 将logs-volume挂载到nginx容器中对应的目录,该目录为/var/log/nginx
- name: logs-volume
mountPath: /var/log/nginx
volumes: # 声明volume,name为logs-volume,类型为hostPath
- name: logs-volume
hostPath:
path: /root/logs
type: DirectoryOrCreate # 目录存在就使用,不存在就先创建再使用
NFS
NFS是一个网络文件存储系统,可以搭建一台NFS服务器,然后将Pod连接到NFS上。
PV和PVC
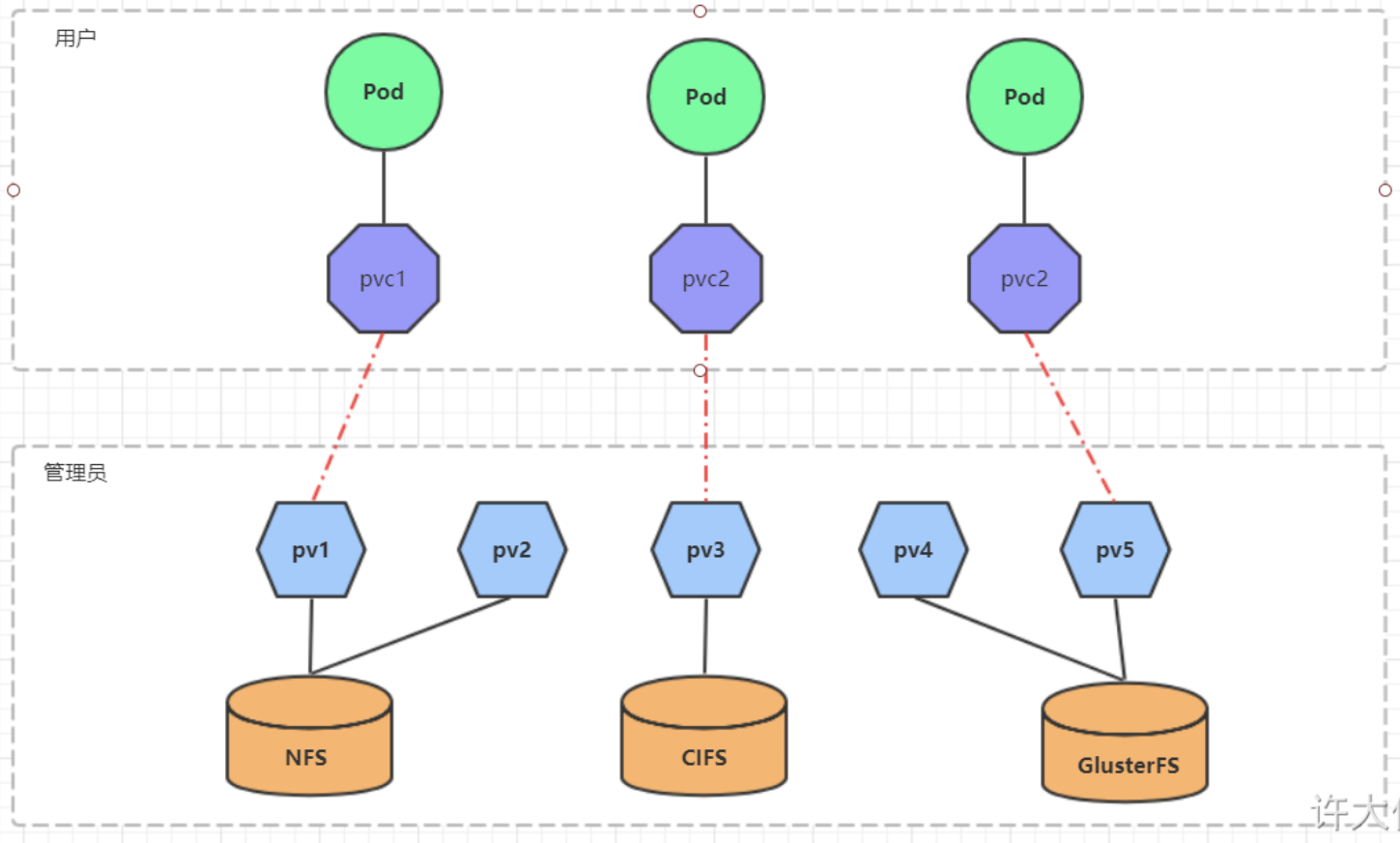
PV(Persistent Volume)是对底层的共享存储的一种抽象,可以设置存储空间。PVC(Persistent Volume Claim)是用户对于存储需求的一种声明,即用户向kubernetes系统发出的资源需求申请。
PV
yaml:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv2
spec:
nfs: # 存储类型,和底层正则的存储对应
path: ***
server: ***
capacity: # 存储能力,目前只支持存储空间的设置
storage: 2Gi
accessModes: # 访问模式
- ***
storageClassName: *** # 存储类别
persistentVolumeReclaimPolicy: *** # 回收策略
具体来说:
-
访问模式(accessModes):描述用户应用对存储资源的访问权限
- ReadWriteOnce(RWO):读写权限,但是只能被单个节点挂载。
- ReadOnlyMany(ROX):只读权限,可以被多个节点挂载。
- ReadWriteMany(RWX):读写权限,可以被多个节点挂载。
-
回收策略( persistentVolumeReclaimPolicy):处理被释放的PV的方式
- Retain(保留):保留数据,需要管理员手动清理数据。
- Recycle(回收):清除PV中的数据,效果相当于
rm -rf /volume/*。 - Delete(删除):和PV相连的后端存储完成volume的删除操作,常见于云服务器厂商的存储服务。
-
存储类别(storageClassName):PV可以通过storageClassName参数指定一个存储类别。
- 具有特定类型的PV只能和请求了该类别的PVC进行绑定。
- 未设定类别的PV只能和不请求任何类别的PVC进行绑定。
-
状态(status):一个PV的生命周期,可能会处于4种不同的阶段。
- Available(可用):表示可用状态,还未被任何PVC绑定。
- Bound(已绑定):表示PV已经被PVC绑定。
- Released(已释放):表示PVC被删除,但是资源还没有被集群重新释放。
- Failed(失败):表示该PV的自动回收失败。
示例:
kind: PersistentVolume
apiVersion: v1
metadata:
name: myvolume
spec:
storageClassName: normal
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
- ReadWriteMany
hostPath:
path: /etc/foo
PVC
yaml:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc
spec:
accessModes: # 访客模式
- ***
selector: *** # 采用标签对PV选择
storageClassName: *** # 存储类别
resources: # 请求空间
requests:
storage: 5Gi
具体来说:
- 访客模式(accessModes):用于描述用户应用对存储资源的访问权限,同样包含ReadWriteOnce,ReadOnlyMany和ReadWriteMany。
- selector:根据label筛选pv
- storageClassName:根据存储类别筛选pv
示例:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: task-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
创建一个包含pvc的pod:
apiVersion: v1
kind: Pod
metadata:
name: pod
spec:
containers:
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","while true;do echo pod1 >> /root/out.txt; sleep 10; done;"]
volumeMounts:
- name: volume
mountPath: /root/
volumes:
- name: volume
persistentVolumeClaim:
claimName: pvc
readOnly: false
配置存储
ConfigMap
yaml:
apiVersion: v1
kind: ConfigMap
metadata:
name: configmap
namespace: dev
data:
info:
username:admin
password:123456
在pod中引用configMap:
apiVersion: v1
kind: Pod
metadata:
name: pod-configmap
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
volumeMounts:
- name: config
mountPath: /configmap/config
volumes:
- name: config
configMap:
name: configmap
可以进入pod查看配置:
>> kubectl exec -it pod-configmap -n dev /bin/sh
>> cd /configmap/config
>> ls
>> more info
如果更新了configMap,pod中的配置信息也会相应更新。
Secret
Secret类似于ConfigMap,专门用于保存机密数据。
示例:
apiVersion: v1
kind: Secret
metadata:
name: secret
namespace: dev
type: Opaque
data:
username: YWRtaW4=
password: MTIzNDU2
在pod中引用secret:
apiVersion: v1
kind: Pod
metadata:
name: pod-secret
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
volumeMounts:
- mountPath: /secret/config
name: config
volumes:
- name: config
secret:
secretName: secret
9 安全认证
RBAC
RBAC(Role Based Access Control):基于角色的访问控制,为对象授予权限。
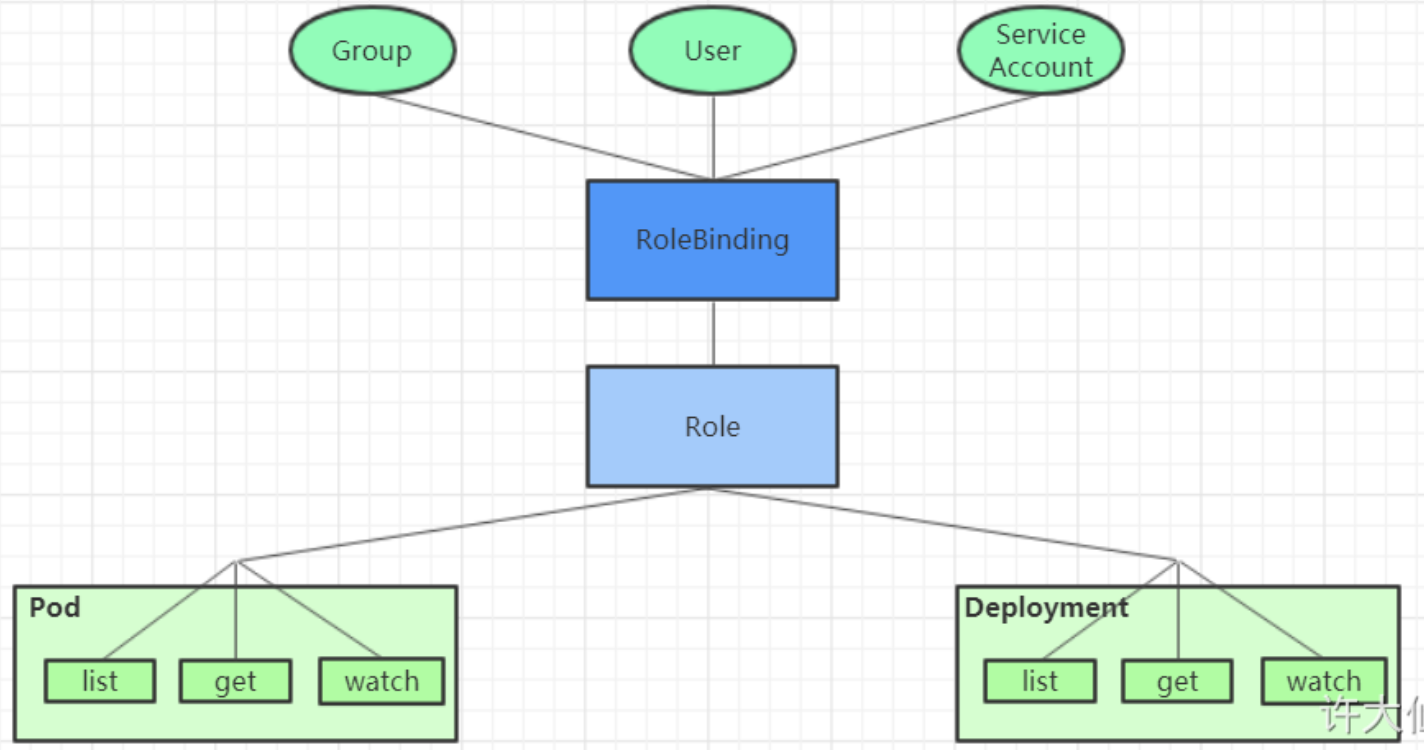
Role/ClusterRole:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: authorization-role
namespace: dev
rules:
- apiGroups: [""] # 支持的API组列表,""空字符串,表示核心API群
resources: ["pods"] # 支持的资源对象列表
verbs: ["get","watch","list"] # 对资源对象的操作方法列表
参数说明:
- apiGroups:"", “apps”, “autoscaling”, “batch”
- resources:“services”,“endpoints”,“pods”,“secrets”,“configmaps”,“crontabs”,“deployments”,“jobs”,“nodes”,“rolebindings”,“clusterroles”,“daemonsets”,“replicasets”,“statefulsets”,“horizontalpodautoscalers”,“replicationcontrollers”,“cronjobs”
- verbs: “get”, “list”, “watch”, “create”, “update”, “patch”, “delete”, “exec”
RoleBinding/ClusterRoleBinding:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: authorization-role-binding
namespace: dev
subjects:
- kind: User
name: username
apiGroup: rbac.authorization.k8s.io
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: authorization-role